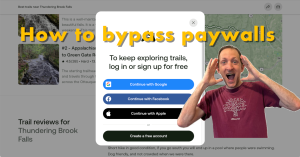
Post Categories News Tutorial Post dateJuly 11, 2025 “How to bypass paywalls” is now on YouTube Post read time19 sec read "How to bypass paywalls" is now on YouTube.
Post Categories News Tutorial Post dateJune 27, 2025 Web-Scrapers & Anti-Scrapers Post read time1 min read Web-Scrapers vs Anti-Scrapers
Post Categories News Post dateJune 8, 2025 My trip to PyCon 2025 Post read time2 min read In May 2025, I made my very first trip to PyCon, which is the...
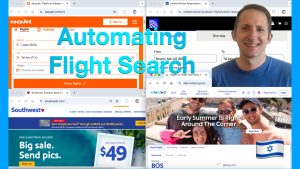
Post Categories News Tutorial Post dateMarch 28, 2025 New video: “Automating Flight Search while Web-Scraping Prices” Post read time18 sec read Automating Flight Search while Web-Scraping Prices.
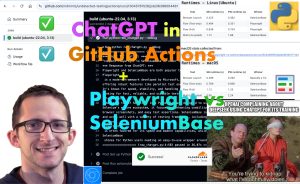
Post Categories News Tutorial Post dateFebruary 18, 2025 ChatGPT in GitHub Actions + Playwright vs SeleniumBase Post read time11 sec read ChatGPT in GitHub Actions + Playwright vs SeleniumBase
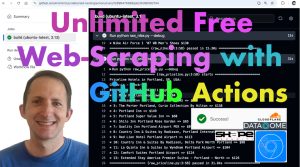
Post Categories News Tutorial Post dateJanuary 14, 2025 New video: Unlimited Free Web-Scraping with GitHub Actions Post read time15 sec read Unlimited Free Web-Scraping with GitHub Actions with Python and SeleniumBase
Post Categories News Tutorial Post dateJanuary 7, 2025 New video: Hacking websites with CDP and Python Post read time20 sec read Hacking websites with CDP (Chrome DevTools Protocol) and Python
Post Categories Tutorial Post dateDecember 4, 2024 HTML Escape Sequences (Reference Guide) Post read time12 min read Know your HTML Escape Sequences!
Post Categories News Tutorial Post dateDecember 2, 2024 New Video: Undetectable Automation 4: “Chrome Devtools Protocol” (with CDP Mode and Python) Post read time10 sec read New Video: Undetectable Automation 4: “Chrome Devtools Protocol” (with CDP Mode and Python) (This...
Post Categories News Tutorial Post dateAugust 21, 2024 New Video: Undetectable Automation 3: “Revenge of the CAPTCHAs” (with UC Mode and Python) Post read time13 sec read New Video: Undetectable Automation 3: “Revenge of the CAPTCHAs” (with UC Mode and Python)...